Domestic ``AI Test Paper''-AIPerf
In the case of computing power, an AI performance benchmark called MLPerf has often jumped into people's attention in recent years.
In order to use this standard to prove the strength, the performance of big "computing power" companies such as Nvidia and Google can be said to have earned enough attention.
As early as December 2018, when MLPerf was first released, NVIDIA based on its Tesla V100, achieved excellent results in six tests including image classification, object segmentation, and recommendation system, and won the best of the audience.
Since then, Nvidia has repeatedly brushed the list. In the latest performance test not long ago, Nvidia broke eight AI performance records with the A100 GPU.
Google did not show any weakness, with 4096 TPU V3 reducing the BERT training time to 23 seconds.
In this regard, Jeff Dean, the head of Google AI, also posted on social platforms:
I am very happy to see the results of MLPerf 0.7, Google TPU has set six records in eight benchmark tests.
We need (change) a larger standard, because we can now train ResNet-50, BERT, Transformer, SSD and other models within 30 seconds.
So the question is, is the MLPerf set of "exam questions" that these "computing power" companies are chasing, really the "only standard for AI performance benchmarking"?
not necessarily.
To achieve the ideal AI or high-performance computing (HPC) benchmark, there are three challenges:
First of all, the benchmark workload (workload) needs to express actual issues about hardware utilization, setup costs, and calculation modes.
Second, it is best for benchmarking workloads to automatically adapt to machines of different sizes.
Finally, using simple and fewer indicators, you can measure the overall system performance of AI applications.
On the other hand, MLPerf, as Jeff Dean said, it has a fixed workload size, which may be a mistake in itself.
Because the increased computing power should be used to solve larger-scale problems instead of using less time to solve the same problems.
And benchmark tests like LINPACK cannot reflect the cross-stack performance of AI without representative workloads.
In response to the above problems, Tsinghua University, Pengcheng Laboratory, and the Institute of Computing Technology of the Chinese Academy of Sciences jointly launched a set of "Chinese AI Test Papers"-AIPerf.
Simply put, the characteristics of AIPerf are as follows:
It is based on the automated machine learning (AutoML) algorithm, which can realize the real-time generation of deep learning models, has adaptive scalability to machines of different sizes, and can test the effect of the system on general AI models.
Calculating the amount of floating-point operations through a new analytical method can quickly and accurately predict the floating-point operations required in AI tasks, so as to calculate the floating-point operations rate and use it as an evaluation score.
So, how difficult is this set of "AI test papers" in China? Scientific or not?
Please continue reading.
What does this set of "AI test papers" in China look like?
Spread out this set of "AI test papers", the full picture is as follows:
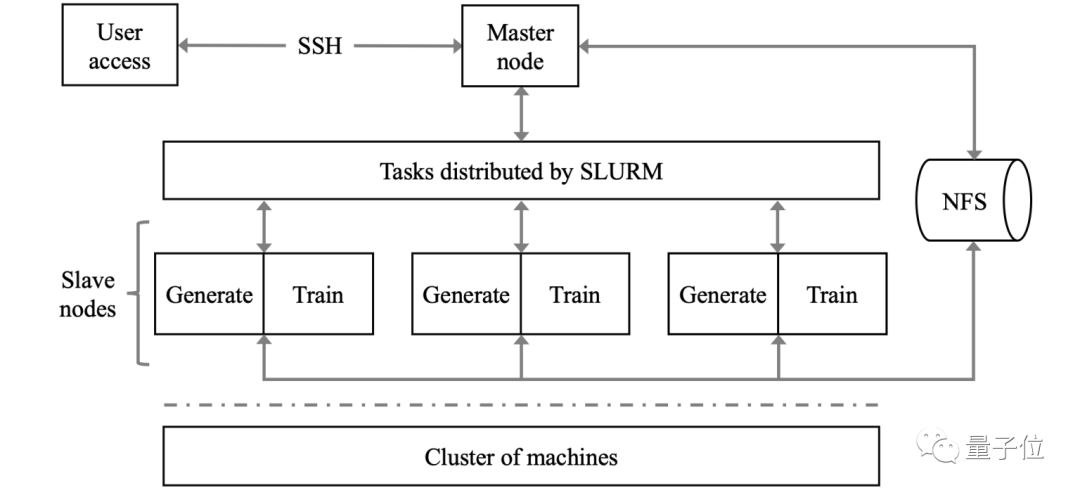
△ AIPerf benchmark work flow chart
As mentioned earlier, AIPerf is implemented based on the AutoML algorithm. In terms of framework, the researchers chose a more user-friendly AutoML framework—NNI (Neural Network Intelligence).
But on this basis, the researchers modified the NNI framework to address issues such as "AI accelerator idle" and "time-consuming model generation".
The workflow of AIPerf is as follows:
Access the master node through SSH, collect the information of the slave nodes, and create a SLURM configuration script.
Through SLURM, the master node distributes the workload in parallel and asynchronously to the slave nodes corresponding to the request and available resources.
After the slave nodes receive the workload, they perform architecture search and model training in parallel.
The CPU on the slave node searches for a new architecture according to the current historical model list (the list contains detailed model information and accuracy on the test data set), and then stores the architecture in a buffer (such as a network file system) for later training.
The AI accelerator on the slave node loads the "candidate architecture" and "data", uses data parallelism to train with HPO, and stores the results in the historical model list.
Once the conditions are met (such as reaching the user-defined time), the run will terminate. The final result is calculated based on the recorded indicators and then reported.
After completing this set of "AI test papers", how should the scores obtained be measured and ranked?
We know that FLOPS is currently the most commonly used performance indicator to reflect the overall computing power of high-performance computing.
In this set of "test papers", researchers still use FLOPS as the main indicator to directly describe the computing power of AI accelerators.
In AIPerf, the floating-point operation rate is treated as a mathematical problem to solve. By decomposing the deep neural network and analyzing the calculation amount of each part, the calculation amount of floating-point number is obtained.
Combined with the task running time, the floating-point operation rate can be obtained and used as the benchmark score.
Once the theory is in place, the experiment must keep up.
The hardware specifications are as follows:

The details of the assessment environment are as follows:

Finally, announce the performance results!
Researchers ran the AIPerf benchmark test on machines of various sizes, mainly evaluating two aspects, namely stability and scalability.
From 10 nodes to 50 nodes, there are up to 400 GPUs. All intermediate results, including the generated architecture, hyperparameter configuration, precision and time stamp at each point in time, are recorded in the log file.
The following figure shows the changes over time of the "benchmark score" and "standard score" (both in FLOPS) evaluated by machines of different sizes.
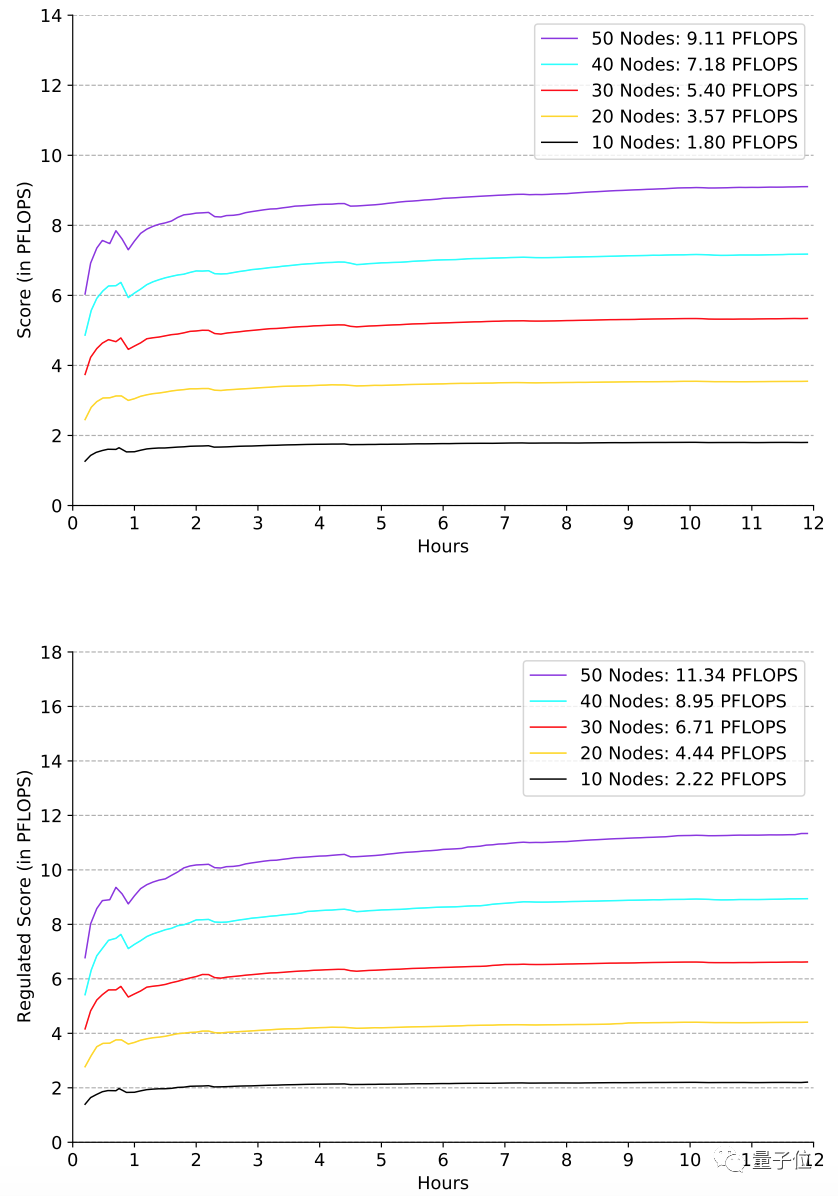
The results show that the AIPerf benchmark test has robustness and linear scalability.
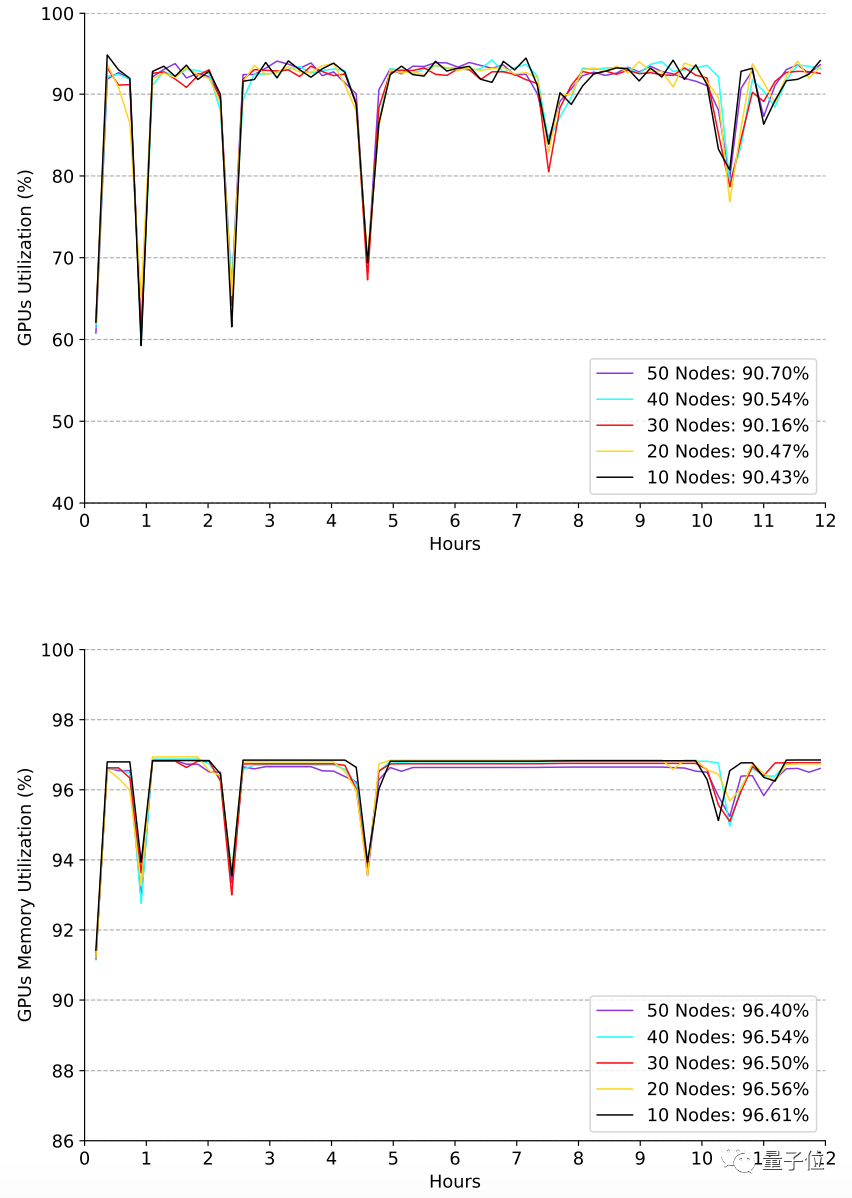
Next, is the relevant evaluation of GPU and its memory utilization under different scale machines.
It can be seen from the figure that the overall calculation and memory utilization of the AI training card is very high (both are greater than 90%). In the transition phase between different models, due to data loading and calculation graph compilation, the utilization rate will decrease.
Why is this "examination paper" produced?
After "viewing the test paper", there is a question to think about:
Why is there a set of AI benchmark tests called AIPerf?
This issue needs to be viewed from the outside to the inside.
First of all, from the appearance, similar to MLPerf and LINPACK benchmark test programs, there are some loopholes and problems in itself:
Either the size of the workload is fixed, and the increase in computing power should be used to solve larger-scale problems, which limits scalability.
Or in the absence of representative workloads, the system's cross-stack computing performance for AI cannot be reflected.
Although such evaluation standards are of certain value and significance at present, the objective deficiencies cannot be ignored.
After all, in the current environment of rapid development of artificial intelligence, computing power is particularly important, and a complete and more scientific "benchmark" will help the development of computing power.
From this point of view, "benchmark test" and "computing power" are more like a pair of force and reaction force.

Secondly, from a deep perspective, it is very necessary to develop computing power.
For high-performance computing, the "TOP500" list was born as early as 1993. From the initial dominance of the United States and Japan to the rise of China's computing power, it is not difficult to see the country's investment in this construction.
The reason is simple. High-performance computing plays a vital role in the development of aerospace, petroleum exploration, water conservancy projects, and emerging high-tech industries in various countries.
However, with the rise of AI, the traditional "solving method" of high-performance computing has changed-AI+HPC is the future development trend of computing power.

In recent years, the TOP500 list can reflect this:
The first ARM architecture HPC to top the list is based on Fujitsu's 48/52 core A64FX ARM.
SUMMIT, ranked second, uses IBM Power+NVIDIA V100.
...
Nearly 30% of the systems on the list have accelerator cards/coprocessors. In other words, more and more systems are equipped with a large number of low-precision arithmetic logic units to support artificial intelligence computing power requirements.
In our country, more and more companies have begun or have already deployed them.
Such as Huawei, wave, Lenovo, are tough to come up with their own products, such as TOP500, MLPerf etc. list in the displayed their skill.
From a practical perspective, you may think that developing computing power is of no use to ordinary people, but it is not.
It just so happens that the "Double 11" shopping mall every year is coming, and behind every e-commerce platform, there is a powerful recommendation system, which is the "guess you like" function that users often see.
Whether the recommendation is accurate or fast depends to a large extent on the strength of the AI computing power.
Moreover, the annual turnover of hundreds of billions of yuan can ensure the success of timely payments, and AI computing power is also indispensable.
...
Finally, back to the original question:
What will be the performance of this set of "AI test papers" issued by China, namely ALPerf, Nvidia, Google and other established computing power companies?


No comments:
Post a Comment