Have a comprehensive understanding of the development history of cloud computing and related technology domains
The technical fields, technical terms and technical products surrounding cloud computing are dazzling. At the beginning of cloud computing, the application development environment was relatively simple. At that time, there were so-called full-stack engineers, which meant that if the development cycle was not considered, one person could handle the entire application software. Today, this title is no longer true. Few people or even an enterprise can fully grasp all the technology stacks related to cloud computing. They may use some of the results completed by others, combined with some of their own proprietary experience, to form a competitive product in a certain market segment, or to deliver the desired output for customers.
Even as a pure user, it is much more difficult than in the past to fully understand the technologies related to cloud computing, to achieve a reasonable structure, appropriate selection, and to successfully complete the entire process of integrated development and deployment. It used to be expensive. Frankly speaking, under the current competition for talents, companies in general industries, even if they have an information department, are unlikely to independently manage such complex development facilities. They will have to rely extensively on the services provided by cloud computing platforms. This brings new market opportunities for solution providers in the software industry. Whoever can provide a friendly application development and deployment environment for digitally transformed enterprises will be able to acquire and retain customers.
This long article is mainly for technical and non-technical managers of large and medium-sized enterprises. I passed the drawing cloud computing technology and market in the field of the development process, introduce the key technology and market milestones, including the core open source project under different technical fields, allowing businesses to cloud computing history and related technical field with a through- understand disk. With a comprehensive understanding, it will be easier for you to see how your company should use cloud computing, and where are the possible market opportunities and challenges in the future?
This article is inspired by the book Digital Transformation published by Tom Siebel in 2019, but I try to combine the actual situation of the Chinese market to explain it in a simple manner.
The formation and structure of the cloud computing market
Today, we can enjoy economic and convenient cloud computing services, mainly from two driving forces, one is the virtualization technology of computing resources, and the other is the effect of economies of scale. The former originated from the Hypervisor virtualization software launched by VMWare after 2000. It no longer relies on a parent operating system and allows users to divide hardware and network resources into multiple units, thereby realizing pooling, sharing and on-demand scheduling of computing resources .
In 2006, Amazon launched the S3 object storage service and SQS simple queue service, creating a precedent for public cloud computing services. Since then, Microsoft, IBM, Google, China's Ali, Tencent and Huawei have all joined the public cloud service market, and the services provided have expanded from basic computing resources to databases, artificial intelligence, and the Internet of Things. At present, this industry has grown into a huge market with annual revenue of 250 billion US dollars.
In the course of more than ten years of development, of course, many companies, products and services have appeared, but in summary, the emergence of these things is basically proceeding along two obvious routes:
Trend 1: From infrastructure, to applications, to application-related platform services
Basic Cloud (Infrastructure as a Service)
The earliest cloud computing service is the most basic cloud host (Virtual Machine). The service provider installs the bare metal on the Hypervisor, divides the computing and network resources into blocks, and sells it. Subsequently, basic services were split into several important basic cloud products such as host, storage, network, database and security, allowing users to flexibly combine and realize flexible billing (currently, most foreign basic cloud vendors provide With a billing accuracy of one second, storage can be billed monthly. For example, the standard monthly storage fee per GB of data for AWS's S3 service is US$0.0125, while the monthly fee per GB for deep archive storage can be as low as US$0.001 per GB).
We generally refer to host, storage, network, database and security-related computing services collectively as basic cloud services. On top of these services, developers need to complete all the technology stack construction, build their own data architecture, develop coding, deploy operation and maintenance, and finally realize cloud applications. Most of the first-generation cloud computing customers are Internet companies. They are not the ultimate consumers of cloud services, but producers.
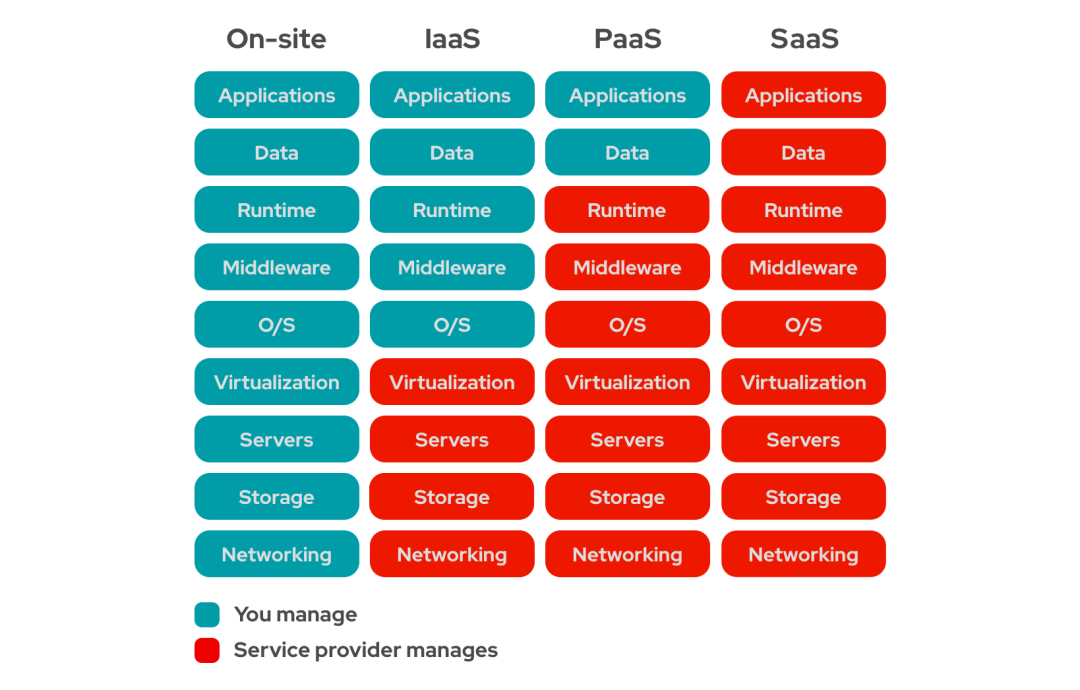
Application as a Service (Software as a Service)
Amazon Web Services and another one almost the same time start-up companies Dropbox is one for individuals and teams to provide file storage and common sharing service business startups. Catch up with AWS when it started, Dropbox directly used AWS's off-the-shelf S3 object storage service, which gave a startup with a small team the opportunity to focus on application development and marketing, allowing Dropbox to pass just a few years the first time to develop into a market share of common file sharing should be used. Most of the big-ticket SaaS companies similar to Dropbox also appeared in the following ten years. They all used the services of the cloud computing platform instead of building their own infrastructure. This also includes a super user "Netflix" (Netflix), whose downstream traffic accounts for as much as 15% of the entire Internet downstream traffic, and is also a customer of AWS.
The Mingdao collaborative application we founded was born in 2011, which coincided with the year when China's cloud computing platform started, so we also avoided a lot of infrastructure construction work. Broadly speaking, the earliest cloud services appeared before the basic cloud company. Salesforce, founded in 1999, is a typical SaaS company, but there was no such industry term back then. In 2016, it is said that Salesforce has also become a customer of AWS. Because of the existence of SaaS service form, cloud computing can indirectly provide services to a large number of small and medium-sized enterprises and non-Internet industry enterprises. Today, almost all enterprises use some SaaS services more or less.
The first wave of cloud computing market development was mainly driven by Internet enterprise users. They have relatively complete development and self-service operation and maintenance capabilities, and they also have increasing usage, making them the most ideal customer group for basic cloud services. To this day, the main customer groups of Alibaba Cloud and Tencent Cloud are still the pan-Internet industry.
SaaS companies are important promoters of cloud computing basic services. Although this category contributes much less economic value than 2C network services, they are well versed in the needs of the enterprise market and promote the application development environment of the cloud computing platform Growing maturity. This is the next step in the trend: platform as a service.
(Development) Platform as a Service (Platform as a Service)
The so-called platform as a service refers specifically to the development platform. When application development work is migrated from local to cloud, it is natural to provide corresponding better solutions in the cloud computing environment. Therefore, the traditional middleware market in the past has undergone changes one after another, and one by one is converted to a certain service on the cloud computing platform. The more common development platform services include:
Communication: provide services such as audio and video communication, message push, SMS, email, etc.
Geographic information: provide services related to maps, positioning and navigation
Application development framework: Provide application development environment and runtime environment
Media services: provide encoding, processing and storage services for media files such as pictures, audio and video
Machine learning framework: Provide machine learning data annotation and model training platform for AI application developers
Sending a verification code short message is also a PaaS service.
As a PaaS service, it is mainly for developers, so in addition to functional services, PaaS vendors should also provide development-friendly peripheral capabilities, such as flexible expansion capabilities, debugging and control permissions capabilities, etc. The more developers involved, the more opportunities for improvement and the lower the average cost of a PaaS service.
Is PaaS service necessarily provided by independent PaaS vendors? Not necessarily. In fact, mainstream PaaS services are mostly covered by IaaS companies. If you open Alibaba Cloud's product list, among hundreds of products, you will find that basic cloud services are only one category, and the other dozen categories are all services related to the development environment. This means that a startup company wants to separate Li-cheng for a successful PaaS vendors need to perform very focused manner, and the product has a clear lead of technology. Once this is done, there is no need to worry about competition with basic cloud companies, because I will talk about the technological development of the cloud computing market later. There are already many technological trends that guarantee the unique advantages of independent PaaS companies in establishing cross-cloud services.
The above is a context in the development of cloud computing services in the past fifteen years, from basic cloud to application symbiosis, to the increasingly rich development platform as a service. Cloud computing covers more and more users, relying on these three levels of services to complement each other.
Trend 2: From public cloud, private cloud to hybrid cloud, to multi-cloud
The second thread relates to the deployment model of cloud computing services (Deployment Model). When the concept of cloud computing was proposed, it obviously referred to public cloud services. Customers do not need to maintain any infrastructure, and they can directly use cloud computing resources like hydropower and coal. But there is always a gap between the reality of business and the ideals of technology companies. Whether cloud computing is a technology or a service, there has been a lack of consensus for a long time.
Before the opening of cloud computing services, many large enterprises and organizations had their own servers. In 2010, the global server market was worth US$50 billion, and most of these servers were sold to enterprises and governments. Enterprises have these infrastructures, should they spend money on public cloud services? Since cloud computing technology is so good, why should I implement it myself? Customers in the government, finance, and pharmaceutical industries are even more unlikely to adopt public cloud computing services without hesitation in the early days of their birth. They have various so-called compliance requirements.
Private Cloud (Private Cloud)
Sure enough, there is demand and supply. In 2010, Rackspace and NASA announced an open source project group called OpenStack. It contains a series of open source software used to build cloud computing services. This means that all users with hardware infrastructure can achieve a technical architecture similar to AWS at a very low cost. Rackspace is an IDC company, and its motivation to do so is obviously very strong. It believes that as long as it helps customers solve the virtualization problem, its own hosting business can also thrive.
Although the software is open source and free, cloud computing-related expertise is still required to implement Open Stack. Therefore, since 2010, there have been many service providers based on OpenStack to help enterprises build private clouds. In China, public cloud service providers have even provided such services. Ten years later, this private cloud trend brought by OpenStack has basically come to an end. Except for a very small number of large users who can afford to maintain their own independent cloud computing platform economically, the vast majority of users simply cannot get economically reasonable returns. Virtualization is only a technical prerequisite for cloud computing services, but not all of its value. Private cloud solutions can never take advantage of flexible resource utilization (large or small) and true economies of scale, unless users are not concerned about economic rationality.

In the Chinese market, key industries may still be unable to use commercial cloud services, but telecom operators and some national technology companies have also established various industry clouds with the help of public cloud service providers. Such as moving clouds, linking through clouds and telecommunications Tianyi cloud is formed in this way, they provide public cloud services for the financial, government, transportation, education and other key industries.
At this point in the story, it seems that the public cloud has won a big victory. However, business reality is back. In the increasingly homogeneous cloud computing service market, do customers have no bargaining power at all? If the customer's needs can not be met, there is always a vendor is willing to Yi Chong- new. So Hybrid Cloud (Hybrid Cloud) came out.
Hybrid Cloud (Hybrid Cloud)
In fact, hybrid cloud is not a unique cloud computing technology, it is essentially a set of communication services. As long as a pile of good enough network equipment and luxurious private line connection, computing equipment anywhere in the world can form a high-speed private network. Even if the client's budget is limited, as long as the requirements for security and connectivity are not so high, they can build an economical VPN network by themselves. The technology around building a hybrid cloud through commercial network connections is called "SD-WAN" (Software Defined Wide Area Network). With a network connection, it is possible to connect customer-owned computing facilities and public cloud computing facilities together, which is called "hybrid cloud".
The benefits of hybrid cloud to customers are obvious. First of all, every enterprise may have basic cloud computing usage, but there may also be short-term surge in demand. With hybrid cloud, customers can purchase their own IT assets based on their own basic usage and operate their own private cloud, while short-term fluctuations can be met through public cloud services. After the peak demand has passed, this part of the expenditure can be removed . Enterprises can also keep basic cloud services that are less difficult to operate and maintain in their own facilities, while at the same time using complex computing services provided by public clouds, such as machine learning platforms. Dropbox is a large-scale SaaS application. It made a lot of structural adjustments in 2016. Most of the services no longer use AWS's public cloud, saving $70 million in annual cloud computing expenses in one fell swoop.
The hybrid cloud strategy has now received dual support from vendors and customers. It puts an end to the black-and-white dispute between public and private clouds and makes the entire IT industry more pragmatic. Many business opportunities have also been born in this. Leading cloud computing vendors such as Microsoft, Amazon, IBM, and Google have all launched their own hybrid cloud solutions. Because of the mainstreaming of hybrid cloud solutions, the competition among cloud computing vendors has begun to shift from the cost of basic cloud resources to the application development ecosystem. Because under the hybrid cloud architecture , customers face new challenges in how to plan for smooth data connections and how to quickly deliver cloud-native applications. Therefore, the ultimate competition in cloud computing is not hardware or software competition, but the competition in the application development and deployment (AD&D) environment.
Multi-Cloud
The concept of multi-cloud is a concept that has emerged in the cloud computing market in recent years. It treats all cloud computing platforms and customers' private cloud facilities as general infrastructure. All applications run consistently and reliably on all clouds. Multi-cloud solutions not only need to be coordinated by infrastructure providers, but more importantly, application development and deployment must be oriented towards the goal of multi-cloud operation.
In 2013, Y Combinator incubator Docker Inc open sourced the Docker project. It becomes an important prerequisite for cross-cloud deployment of applications. Docker allows users to package complex applications, data, and dependent environments, including the operating system itself, into a "container", which can run consistently in any computing environment through a standard Docker engine. With this technology, transferring an application system from Alibaba Cloud to Tencent Cloud is as simple as transferring a file. There is no boundary between cloud and cloud. Why do Windows and mac OS applications are never compatible, while cloud computing vendors watch these things happen? Very simple, because the entire cloud computing technology ecosystem is built on open source software, no matter how big Amazon is, it is only a service provider and it collects rent. On the other hand, customers increasingly value autonomy and controllability. They don't want to be locked in by a single cloud computing company. After all, their customers and transaction data are all running on cloud computing, which is the lifeblood of all companies.

In 2015, Google open sourced the Kubernates project to make multi-cloud solutions even better. K8S can automatically orchestrate the creation and expansion of containers. This means that no matter how complex the application is, it can perform unified operation and maintenance in a multi-cloud environment. For example, if a certain type of storage is used up, you can temporarily buy some Amazon storage. When the data is out of date, it is automatically transferred to low-price cold storage services on a regular basis.
With the multi-cloud technology framework and services, it also means that the cloud computing platform must provide extensive support. Alibaba Cloud certainly hopes to sell more cloud hosting services, but if the technical framework is backward, customers will be lost. Therefore, cloud computing platforms around the world are currently unhesitating to support the multi-cloud strategy, hoping to continue to exist as a professional service provider in this process.
The multi-cloud strategy also has a great impact on application developers. First of all, developers must plan according to the cloud computing environment from day one, support multi-cloud deployment, auto-scaling, and adopt a microservice architecture to implement container deployment. Secondly, application developers can also benefit from such an architecture. Because it allows customers to obtain proprietary software as simple as applying SaaS, the only difference is that applications and data run in a customer-controlled computing environment, but the software itself is based on a single code base (Single Code Base). Our Mingdao Cloud was originally a SaaS application. Customers only need to register on mingdao.com to use it. Now, through container technology, our customers can also install and upgrade in their own cloud computing environment. These all depend on the multi-cloud technology architecture.
Earlier we mentioned that the competition of cloud computing companies will migrate to the application development and deployment environment. So what does it specifically refer to? It is about four technical areas surrounding cloud computing. Tom Siebel summed up them as cloud computing itself, big data, artificial intelligence and the Internet of Things.
Next, we will introduce one by one the digital technology fields that have been developed with cloud computing in the past 15 years. It is precisely because of the popularity of cloud computing services that these emerging technical fields have been catalyzed. In turn, the development of these technical fields has made modern cloud services more perfect and of course more complex. It is these complexities that make the digital transformation of the enterprise a lot of resistance. Compared with the earlier basic informatization work, the scope of technology that enterprises need to recognize and master is much broader. Therefore, when we introduce a brief history of the development of cloud computing, we must also introduce the development of related technology domains.
Cloud computing related technical fields
Big Data
Before the emergence of the concept of big data, the technology of data storage, processing and analysis already existed. With the decline of storage costs and the enhancement of elastic computing capabilities provided by cloud computing, more and more data scenarios can no longer be processed by traditional database technologies. These new scenes can be summarized as three characteristics of high data volume (Volume), high frequency (Velocity) and multiple data types (Variety). For example, in the fields of e-commerce, finance, and the Internet of Things, the system often generates a large amount of data in a short period of time. These data will even produce bottlenecks in the process of storage, not to mention the real-time calculation and analysis. Therefore, since the search engine era, big data-related technologies have been gestated.
MapReduce and Hadoop
The overlord of search engines, Google, was founded in 1998. A few years later, the amount of data carried by Google's search service is already an astronomical figure, and it is increasing at the speed of light. Traditional data processing technology completely relies on the paving of hardware computing power, which will make Google overwhelmed in future development. In 2004, Google internally introduced the GFS distributed file system and the distributed computing framework MapReduce. The former solves the limitation of a single hardware resource. The latter uses a series of mathematical principles to slice and store multiple types of data in specific partitions. This design can greatly improve the efficiency of future calculations and analysis. The technical principle of MapReduce is the most important foundation for the development of big data technology.
Soon, the open source software field began to respond to this technical solution. The founder of the Lucene project, Doug Cutting, officially independent of the Hadoop open source project in 2006, which included a distributed file system, scheduling tools on cluster resources, and the core Big data parallel processing development framework. With Hadoop, industries that face massive data analysis problems have had better solutions. Only around 2006, the main application industry was the Internet industry itself. Yahoo,
China's Baidu and others soon applied Hadoop to solve the problem of storage and retrieval of massive data.

Hive, Spark and streaming computing
In the following years, Hadoop-related big data processing technology continued to be enhanced. Facebook's open source Hive analysis tool uses higher-level and abstract languages to describe algorithms and data processing procedures, and can use SQL statements for big data analysis, which greatly reduces the threshold for users and improves the application efficiency of big data technology. Don't underestimate this improvement, it allows most existing data analysts around the world to easily master big data technology.
In 2009, the AMP laboratory of the University of California at Berkeley developed the Spark open source cluster computing framework, which provides better capabilities and versatility by improving APIs and libraries. And Spark's feature is that it can store data in memory, so data processing and query efficiency is a hundred times faster than the MapReduce framework that uses hard disk storage. Currently, Spark has joined the Apache Software Foundation, becoming a star project in the Apache open source project, and is regarded as the most important tool framework in the field of big data technology.
The technology stack so far has basically solved the need for batch processing and analysis of massive data. For example, if retail companies need to study customer and transaction data to segment their customer groups, these technologies are sufficient. However, the development of digital technology will always stimulate more advanced demand. For example, in online retail, the behavioral data of products and customers are constantly occurring. We hope to calculate immediately when the data occurs, and push a personalized coupon to customers in time, instead of timing. Certain batch computing requires a branch of big data technology—streaming computing.
Common Framework flow calculations include Storm and Spark Stream and Flink, they pay in retail and e-commerce industry is easy analysis , financial risk control, monitoring the situation of things in the car networking autopilot and other fields have been widely used . In 2019, Alibaba bought Flink for US$100 million because the search and product recommendations in Taobao and Tmall we used, including the real-time monitoring of large-screen data on Double 11, were all driven by Flink. Flink intercepted the GMV value after the last second of Double Eleven with almost no delay, showing its performance in real-time data processing.
NoSQL database
The NoSQL (non-relational) database market is also developing simultaneously with big data technology. In the last century, most commercial databases were relational databases, which used SQL language for data processing and query. After the development of big data technology, technical experts discovered that the database can store data in different forms, which can greatly reduce the preprocessing workload in the data analysis process. Therefore, from around 2009, various NoSQL databases began to enter the market.
The following figure is the classification method for NoSQL database types on Wikipedia:
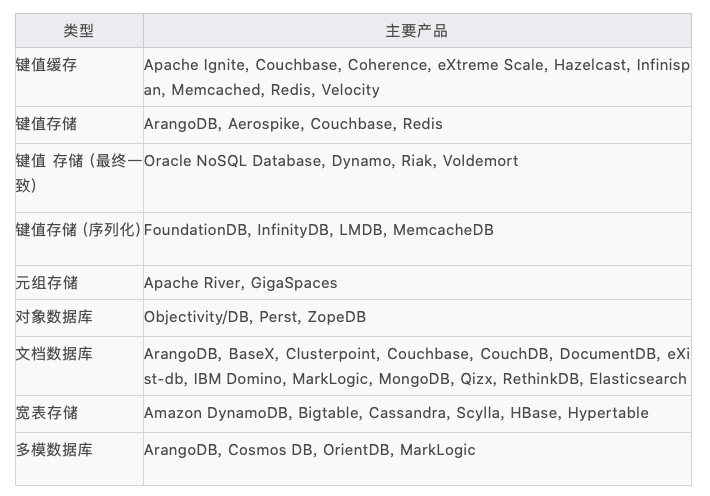
Readers can ignore the detailed technical language, and only need to understand that different types of NoSQL databases will be beneficial to application development in specific scenarios. For example, the document database is stored in the JSON format, and different data structures can be defined at will, and the horizontal scalability is very strong (the query efficiency can be guaranteed after the data size increases). Our worksheet at Mingdao Cloud uses the document database MongoDB as a storage solution.
NoSQL databases generally support distributed file systems, so they all have strong horizontal scalability. Compared with relational databases, NoSQL databases mostly do not have transaction consistency, but this sacrifices exchange to obtain the efficiency of data processing, so it is a common storage solution related to big data technology.
Big data service on cloud computing platform
Above we have introduced various important technology stacks on which the development of big data technology depends. Obviously, big data technology is relatively more complex than traditional application development. It not only involves complex programming frameworks, but also requires a professional operation and maintenance system. This makes it difficult for most ordinary enterprise users to build a big data development environment by themselves. Therefore, in addition to basic cloud services, cloud computing platforms have also begun to combine cloud computing resources to provide big data services. MaxCompute on Alibaba Cloud is a fully managed big data SaaS service. Users don't even need to manage the host infrastructure and pay directly for the amount of big data computing tasks. By the way, this model of directly providing computing services to developers is called "serverless" computing. Its purpose is to simplify the operation and maintenance tasks in development work and allow developers to focus on application development. . Not only in the field of big data, in other technical fields such as AI and the Internet of Things, serverless service models are increasingly becoming the mainstream. E-MapReduce is a complete set of big data-related PaaS services. Users can choose to use ready-made services to complete deployment on cloud hosts under their control. Customers mainly pay for basic cloud resources. Similar to Alibaba Cloud, other cloud computing platforms such as Amazon AWS also provide a wealth of big data-related platform services.
Application field
We mentioned earlier that big data technology originated from search engine applications. In the following ten years, its main application scenario is still in the Internet field. The most common applications include computing advertising (based on user and content data to dynamically determine advertising strategies and pricing), content retrieval and recommendation (Baidu, Toutiao), product recommendation and marketing campaign optimization (Taobao, Pinduoduo). Don't underestimate these few scenes. They are almost related to every minute and second of Internet users' online process, so they create huge economic value.
Of course, the value of data is not limited to the Internet industry. Almost every industry has the opportunity to discover the value of data with the help of big data technology, improve operational efficiency, or discover new business opportunities. The financial industry is an early beneficiary. Risk control in bank loan business, fraud detection in retail and settlement business, actuarial and individualized pricing in insurance business, and futures pricing and stock price prediction in the securities industry are all creating wealth.
Big data is also playing its role in research and development. In the field of biomedicine, big data technology is helping to shorten the cycle of drug research and development and increase the success rate; the synthetic chemistry industry is also using big data and machine learning technology to speed up the discovery of new materials. Some people even think that data science will become a new scientific research method besides experimentation, deduction and simulation, and become the "fourth paradigm."
Big data has already had practical applications in urban transportation, social governance, energy transmission, network security, aerospace and other fields. But outside of these areas where capital investment is intensive, the application of big data in general industries and enterprises still has a tortuous road. This is not because big data technology is not perfect, but many industries have not been able to clearly abstract the value of big data applications and the methodology that can be implemented. As mentioned earlier, cloud computing and big data are still vague technical tools for ordinary small and medium-sized enterprises. It is also difficult for ordinary enterprises to hire big data experts, and professional service enterprises have not yet found the use of their technical expertise to provide universal Effective opportunities for service. The application of big data in the general field is still at the conceptual stage. Therefore, most of the big data technology companies that have emerged in the past few years are still serving industries where large customers such as finance, public security, transportation, and energy are concentrated.
The key points of the breakthrough may be in two aspects. One is that the big data technology stack itself is very complex. The current tools still rely on specially trained computer experts. The industry has not abstracted a general application model, nor can it provide a SaaS-like model. Friendly application interface. This is worth exploring by cross-border experts in the field of data technology and enterprise applications. Second, the digital construction of enterprises has just begun, and many enterprises lack a stable and reliable data collection and recording process. If there is no data flow, there will naturally be no big data applications. Therefore, it may take five to ten years for big data technology to be widely used.
Artificial Intelligence (Artificial Intelligence)
The concept and basic principles of artificial intelligence originated as early as the 1950s. Early artificial intelligence research was concentrated in computer laboratories such as the University of California, Berkeley, MIT, Stanford, and the University of Southern California. The neural network algorithm that has been commercialized today comes from the "Perception Element" paper published by Professor Minsky of the Massachusetts Institute of Technology more than half a century ago, but the computing power of the computer was so weak at that time that any calculation theory The above assumptions are difficult to put into reality. Therefore, artificial intelligence technology has remained in theoretical research and part of unsuccessful practice for as long as fifty years.
Although the field of artificial intelligence has experienced a long winter, the hypothesis that the machine it proposes to learn from humans and ultimately can do better than humans in a particular field is absolutely true.
AI recovery after the millennium
After 2000, there were several major reasons that promoted the revival of the concept of artificial intelligence. First of all, because of the existence of Moore's Law, the computing speed and unit storage cost of computers have developed to a new stage at an exponential rate. Cloud computing and big data technology also allow computers to process terabytes or even petabytes of data at a very fast speed. Second, the rise of network services has produced rich data in many fields. The businesses of Google, Netflix, and Amazon are like data machines, which can generate massive amounts of user behavior data every second.
Third, in the research on the mathematical methods of artificial intelligence, three scientists from AT&T Bell Labs (Tin Kam Ho, Corinna Cortes, and Vladimir Vapnik) have made outstanding progress in the field of machine learning. Machine learning technology can solve complex and uncertain nonlinear problems through linear mathematical formulas. In the process of solving different problems, machine learning theoretical methods and practices have been clearly verified. The earliest Internet companies, including Google, Facebook, Linkedin, etc., not only provided massive amounts of data in this process, but also obtained huge results from the research process. Especially Google, it is the most important believer and promoter in the field of machine learning and its branch deep learning. In 2010, Google established Google Brain, an internal organization focused on artificial intelligence research, and later acquired British company DeepMind. The latter defeated the human Go champion Lee Sedol in March 2016.
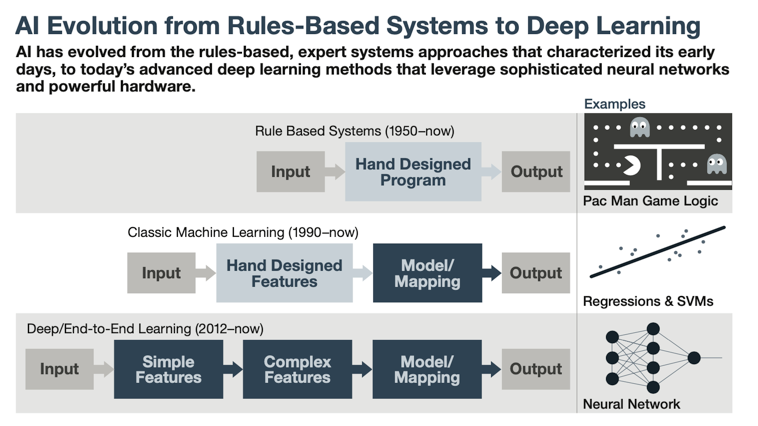
The picture below is an illustration of the evolutionary history of AI technology by Tom Siebel in Digitlal Transofrmation, showing the history of major technological iterations from the 1950s to the present.
Machine Learning (Machine Learning)
Machine learning is the most important driving force behind the recovery of AI. Its rise marked the end of a long detour for artificial intelligence. To make machines do better than humans, it is not to rely on humans to teach machine rules, but to let machines learn from historical data. For example, the most common machine learning scenario-object recognition, if you want the machine to find "cats" from various photos, just let the machine learn the photo objects of various cats. The machine learning algorithm will summarize the vector features behind the cat images used for training into a predictive model , and let this model predict the probability of a cat in any new picture. In the same way, speech recognition, language translation, face recognition, etc. all use similar principles. The larger the amount of data in the feeding algorithm, the higher the accuracy of the prediction.
Machine learning applications can be divided into supervised learning and unsupervised learning. The former requires manual participation in the identification of training data, while the latter uses mathematical methods to automatically cluster similar objects. In the absence of training data, unsupervised machine learning will play a greater role.
A branch of machine learning is called Deep Neural Network (DNN), and its design has highly referenced the connection structure of human brain neurons. In a deep neural network, data is sent to the input layer, and the result is generated from the output layer. There are multiple hidden layers between the input layer and the output layer. Each layer will infer the various features of the input data, and finally get More accurate prediction results. AlphaGo that defeated Li Shishi is an algorithm based on deep neural networks. However, DNN is still a black box for users. The designer does not need and will not know what specific features each layer in the neural network is judging, and how it decomposes the features. Behind it are highly abstract mathematical methods. No matter how mysterious it is, deep neural networks are indeed powerful. It not only has superb self-learning capabilities, but also simplifies a large number of complex and time-consuming feature engineering in traditional machine learning (Feature Engineering, which uses industry-specific knowledge to tune the machine The process of learning algorithms).
TensorFlow
In 2015, Google open sourced the internal TensorFlow framework and began to provide the artificial intelligence computing framework as a cloud computing service to the outside world. After the core open source libraries, TensorFlow has also successively launched Javascript versions to meet the development and training of machine learning models on browsers and Node.js, as well as the Lite version deployed on mobile devices and IoT devices. In addition, TensorFlow Extended is an end-to-end machine learning production platform that provides a programming environment and data processing tools.
Of course, TensorFlow is not the only machine learning framework, Caffe, Torch, Keras, etc. are all. They are all open source without exception. In the forefront of cloud computing, open source software is a common strategy. Why would such complex and advanced software choose open source without hesitation? On the one hand, because the framework product itself does not directly contain commercial value, the value requires developers to create a second time. On the other hand, under the premise of the business model of cloud computing services, providing encapsulated artificial intelligence services through APIs is a Very easy to implement commercial means. Operators of these open source products do not need to charge for the framework.
Artificial Intelligence Service
In fact, even if you don't use these machine learning frameworks, you can use artificial intelligence services directly. Cloud computing platforms at home and abroad are already providing various artificial intelligence services through APIs. These services have been completely encapsulated into application development interfaces. Developers do not need to understand and deal with complex machine learning processes at all, as long as they treat themselves as users.
However, these services are very specific and specific, and there is no general AI interface. Each interface can only solve a specific type of problem for users. The following is the distribution of services under the Alibaba Cloud AI category. You can see that these services are all related to a specific need of the user. For example, voice recognition allows mobile developers to develop applications that allow users to control functions directly through voice. Face recognition can identify face objects in images and realize identity comparison verification.
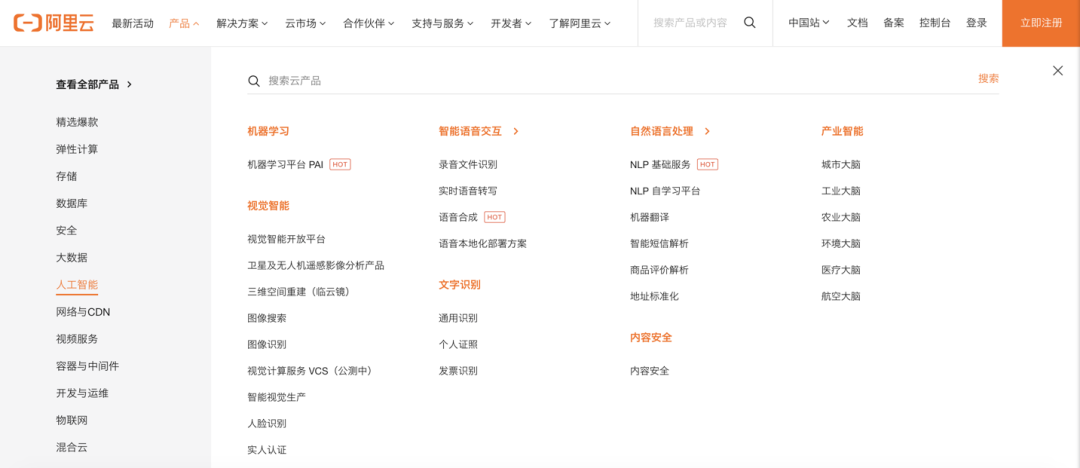
How much does it cost to provide such services once? On cloud computing platforms, most of these AI application development interfaces are charged according to the number of times or the number of times per second (QPS). For example, it costs about 1-5 cents to identify the information on an ID card. Sounds like a lot?
In fact, companies engaged in artificial intelligence technology are not just cloud computing platform providers. For example, in the Chinese market, Face ++, IFLYTEK , Shang Technology , Cambrian, Union Brother and so are expertise in the field of computer vision, speech, robotics. However, their specific positioning makes it difficult for these companies to provide universal developer services. Because developers often want to obtain a package of services on a cloud computing platform, and users' basic cloud resources are also purchased from the cloud computing platform. As a developer, it is very important to have a unified and complete application development environment.
Therefore, in the commercialization of artificial intelligence, there are still many companies taking advantage of their dedicated technology to solve more subdivided problems. For example, iFLYTEK mainly provides solutions for education and judicial industries through its technical accumulation in voice and natural language processing. Many of the text records of Chinese courts are now realized through automated voice transcription. Shangtang Technology and Megvii Technology mainly provide software and hardware integration solutions in the field of smart cities and security. There is also a group of startups focusing on solving high-value autonomous driving problems and deriving more segmented AI chip design and manufacturing companies from them.
Technology stack and talent
The AI-related technology stack is an extension of the big data technology introduced earlier. In other words, there is no artificial intelligence project that can be separated from data acquisition and processing. It is very difficult for non-cloud computing professional enterprises to combine so many development frameworks and microservices. In addition to the complexity of the technology stack, developers also need to figure out the process of acquiring and processing large-scale training data. This cost will surely become a factor constraining enterprise investment in a short time.
Cost is still relatively easy to overcome, because as long as the problem is worth enough, companies with long-term values are always willing to invest. But the more deadly problem lies in the fierce competition for AI-related talents. A team capable of developing AI applications needs to include big data-related database experts, algorithm experts proficient in mathematical modeling, and senior programmers proficient in programming languages such as C++ or Python. At the same time, they cannot do without technically literate business experts. participate. At the current stage, cloud computing giants and professional companies have attracted most of the talents like iron magnets, leaving ordinary companies unable to obtain them.
Considering the complexity and professionalism of AI technology, it is very likely to be like cloud computing services. Most companies will only become user-level roles. This leaves room for professional developers to innovate and see who can do enough Reasonable abstraction can combine AI services that are easier to use and face common business scenarios.
Internet of Things
The popularization of the Internet of Things detonated by consumer products
The popularity of cloud computing services not only provides users with the economy of elastic scaling, but also provides a ubiquitous connectability. As long as any computing devices are connected to the Internet, they can access each other through the TCP/IP protocol. Before the development of the Internet of Things technology, this interconnected value was limited to traditional computing devices, that is, servers and personal computing terminals. In the personal, family, and corporate world, there are still a large number of non-traditional computing devices that are not connected to this digital world.
Automobiles, home appliances, personal wearable devices, and manufacturing equipment in factories now have the conditions to access the Internet, and there are more and more interconnected smart products circulating in the market. When the connected devices are abundant to a certain extent, various intelligent scenarios can be truly realized. IHS Markit predicts that by 2025, the total number of connected devices worldwide will reach 75 billion. The interconnection of everything is the vision pursued by the Internet of Things technology.
Unconventional computing devices with digital connectivity capabilities have appeared in the 1990s, such as cameras that can be connected wirelessly. Devices with true medium and long-distance connection capabilities first appeared in the retail and industrial manufacturing fields, including the Industrial Equipment Interconnection Protocol (M2M) developed by Siemens and General Electric. At that time, these devices could already be connected to the factory's control center through a low-speed wireless LAN using the IP protocol. Such a network is called Industrial Ethernet. But the commercial Internet did not begin to develop at that time, so the emergence of M2M can only be regarded as a partial development of the Internet of Things technology.
The beginning of the Internet of Things is still being promoted through the consumer product market. In the early 2000s, LG took the lead in launching home appliances that can access the Internet. A networked refrigerator sells for as much as $20,000, which obviously cannot really drive the market. In the following years, consumer electronic products such as Garmin GPS and Fitbit smart bracelets began to gain greater production and sales, thus driving the development of related low-power chip industries. By 2011-12, more star-rated products appeared in the consumer electronics field, including the home sensor Nest, which was later acquired by Google, and the Hue smart bulb launched by Philip. In the Chinese market, smart phone manufacturers represented by Xiaomi have begun to expand into the field of Internet of Things products, launching a series of smart devices and home gateway products around individuals and families. Apple also officially entered the wearable product market in 2015, launching the Apple Watch and later the smart speaker HomePod. Google and domestic Internet giants have also joined the competition for users and data through new personal digital devices. At present, the global wearable product market has maintained an annual growth rate of more than 40% for many years.
The mass production of personal and home smart devices has promoted the development of protocols related to the Internet of Things and the reduction of component costs. During this period, key transmission and communication protocols such as Bluetooth 5.0, WiFi-6, IPv6, NFC and RFID have been further developed, which has further improved device energy consumption and connection speed. At the same time, cloud computing basic services and big data processing technology also played a key role. IoT devices often generate a large amount of data in a short period of time. Without the big data technology stack mentioned above, traditional database tools cannot carry it. At the same time, cloud computing is also a sea of device data. Today, almost all IoT technologies The platforms are all built on cloud computing platforms, and they are a typical intergrowth industry.
The technology stack of the Internet of Things
The technology stack related to the Internet of Things is very comprehensive. It spans software and hardware, including hardware technologies related to perception and detection, as well as software technologies for network transmission and application construction. Until today, the technology stack related to the Internet of Things has not been completely stabilized, and it may even maintain multiple characteristics for a long time. But in summary, the entire technology stack still has some hierarchical characteristics.
The industry generally decomposes the technical architecture related to the Internet of Things into four layers, which are defined as the device sensing layer related to the physical environment, the network layer related to data transmission and communication, the IoT-related platform management layer, and the ultimate realization of user value. Business application layer. Whether it is for the consumer market or the enterprise market, the IoT system will have these four levels.
The device sensing layer is composed of various types of sensors, interactively accessible hardware modules and their embedded software. Such as temperature and humidity sensors, cameras, power switches and sockets and gateways. The sensing layer device not only obtains data in one direction, but may also receive instructions from the outside world to change the hardware state (such as a smart lock). The industry generally refers to this level as "Edge".
The technology stack of the device sensing layer is mainly composed of an embedded system developed by software and hardware. The smartphone we use is essentially an embedded system, but its embeddedness is very complete, even no less than a standard computing device. Embedded system development has gone through the early stages of single-chip microcomputer and embedded operating system/CPU. At present, the forefront is SoC (System on Chip), which fully integrates all embedded software of a dedicated system on an integrated circuit. Today's smart phones, smart TVs, etc. are all integrated by several SoCs. In the embedded system, the software program solidified on the hardware can even be updated, and most of this update can be realized by connecting to the Internet. This kind of upgrade is called OTA (Over-the-air) update.
In addition, the device sensing layer also needs to solve the problem of device access protocol. The Internet of Things system currently supports the IPv6 protocol extensively. IPv6 can provide the total number of global IP addresses up to 2 to the 128th power. This is an astronomical number that can ensure that any IoT device can have an independent IP address, thereby achieving unique addressing in the world. When the global Internet of Things devices reach hundreds of billions, or even trillions of magnitude, IPv6 is indispensable.
The network transmission layer must solve the data transmission problem between the sensing device and the computing device, and finally between the platform management layer. According to different connection properties, it can be divided into short-distance, medium-distance and long-distance types, as well as wired and wireless types. Among these connection protocols, Bluetooth, NFC, Wi-Fi, radio frequency (RFID), 4G and 5G are more commonly used. These transmission protocols are generally designed directly on the on-board system on the device side, and provide accessible addresses through the IP protocol. Developers need to make reasonable choices based on the distance, speed, power consumption, and cost of the connection.
The IoT platform layer is a vital part of the IoT system, and its appearance also marks the birth of the IoT system based on the cloud computing platform. The core role of an IoT platform is to manage thousands of IoT devices, including their status, data reporting and reception, establishing control over them, grouping devices for operation and maintenance, and being able to push updates from the cloud to the edge. (OTA). At the same time, the IoT platform must also borrow the big data technology stack mentioned above to process the data reported by the device and use various databases to complete storage. The most important type of database is the time series database.
A more complete IoT platform also includes the ability to establish automated workflows around device data, data analysis tools, and the design of data development interfaces for higher-level application development.
At present, mainstream cloud computing platforms provide customers with an IoT technology platform that combines basic cloud and big data related services to obtain value-added business income. Alibaba Cloud, AWS, Azure and Google Cloud all have specialized solutions. There are also specialized IoT platform technology companies at home and abroad that build their solutions on the basic cloud or provide cross-cloud services.
The IoT platforms of enterprise software vendors such as Oracle, Salesforce and Microsoft Azure not only provide the above-mentioned basic services, but also combine the advantages of their own enterprise application suites to provide a one-stop IoT application development platform. They are more suitable for the construction of enterprise IoT systems.
The top application layer is the least standardized part of the entire IoT technology architecture. The application layer ultimately uses the connected devices and data for specific business scenarios. For example, a shared power bank is an Internet of Things system, and its application layer includes a rental and payment system for the C-side, a business-oriented equipment status report, a revenue settlement system, and an equipment operation and maintenance management system for the operation department. Switching to another IoT scenario, the composition of the application layer may be completely different.
Edge computing and AIoT
The basic idea of the technology architecture of the Internet of Things is hierarchical division of labor. The sensing layer mainly obtains data and establishes control of the physical hardware. The data is connected to the computing platform through the network layer, and the calculation is done in the cloud. However, with the enrichment of IoT application scenarios, the expansion of equipment scale, and the development of chip technology, the concept of edge computing has begun to be recognized. The so-called edge computing is to use the computing power of the device and neighboring gateways to process and store data, reduce data transmission with the cloud, and achieve faster application response. In addition to speed improvements, edge computing can also significantly reduce cloud computing and data transmission costs. For example, for a large video surveillance network, if the camera transmits all video stream data to the cloud, the cloud computing power requirements and costs will be very high. And if necessary visual calculations (such as identifying anomalies) are implemented inside the camera device, the efficiency of the entire IoT system will be greatly improved. Another example is the widely used face authentication and recognition system. If you cannot rely on the computing power of local devices, the high-frequency usage of one billion users will overwhelm the cloud platform.
The above two examples show that edge computing is often related to artificial intelligence applications. The device side often completes pattern recognition artificial intelligence algorithms, so special chips are often needed. The Jetson series modules launched by Nvidia are specifically for edge computing scenarios. These chip modules are installed on edge devices such as robots and self-driving cars, so this group of technical products is also called "autonomous machines." Because of the combination of the Internet of Things and these artificial intelligence applications, this set of technical solutions is also often referred to as AIoT.
Application field
If around 2012 is regarded as the beginning of the development of cloud computing-based IoT platform technology, in only about eight years, the application of the Internet of Things has developed very extensively. It's just that we are in it and enjoy the convenience it brings, and we may not be able to perceive its existence. This rapid development process has largely benefited from the simultaneous development of basic cloud computing services and big data technology stacks.
In the field of consumer applications, personal wearable devices have evolved from watches and bracelets to miscellaneous items such as earrings and rings. In the field of smart home, the home appliances, door locks, photos, switches, speakers, etc. we can see are already Internet devices. In the personal and family fields, the Internet of Things technology competition is no longer important, and the focus of competition has shifted to the content ecology and user network effects. In these areas, Apple, Google and domestic Huawei, Xiaomi, etc. have firmly occupied the leading position. The Xiaomi ecological chain mainly refers to a group of consumer electronics companies that rely on the Mijia system.
In the fields of industry, agriculture, transportation, energy and social management, the application scenarios of the Internet of Things are more extensive. Our streets have been densely covered a variety of cameras, these cameras through dedicated web network to build the eye in the sky system; the power transmission network and power unit terminal on our heads also have completed the smart grid transformation; the mines and sites are also cloth Full of various safety monitoring equipment. These are all major IT investments in the last ten years. It is expected that such construction and renewal will not end in the next ten years.
The future of cloud computing
This article is mainly a review of the past fifteen years of cloud computing. The speed of technological development is so fast that it is difficult for us to predict what will happen in the next fifteen years. At the end of this article, I just make a brief summary of the current cloud computing market trends. They are even happening, but we don’t know which giants will be subverted by the development of these technology trends and which stars will be born.
The cost of storage and computing will fall further, but consumption will increase simultaneously. Considering that a large number of global computing services have not yet been transferred to the cloud computing environment, the computing power of basic cloud services will continue to increase in the next ten years, and the unit price of services will continue to decline.
Cutting-edge technologies will continue to be integrated into cloud computing platforms, including quantum computing, AR/VR, blockchain, etc. Especially for those applications that rely on massive data computing power and elastic computing resources, cloud computing is the track that enables them to grow faster.
The core competition of cloud computing will focus on the superiority of the application development environment. Who can provide a cheap, complete and cutting-edge development technology stack environment, who can get more developers and users. When developers and users choose a cloud service provider, they actually make a choice for end users.
Multi-cloud, or hybrid cloud environment has become a long-term enterprise application strategy. Cloud computing users will use the edge, various cloud computing service providers, and their own IT facilities.
The cloud computing development technology stack will become more and more complex, which will make the division of labor in the application development field more clear. Application development for end users will become more concise, and the ways of application generation will become more and more diverse, without coding, and there will be more and more service providers relying on ordinary business users to build applications.


No comments:
Post a Comment